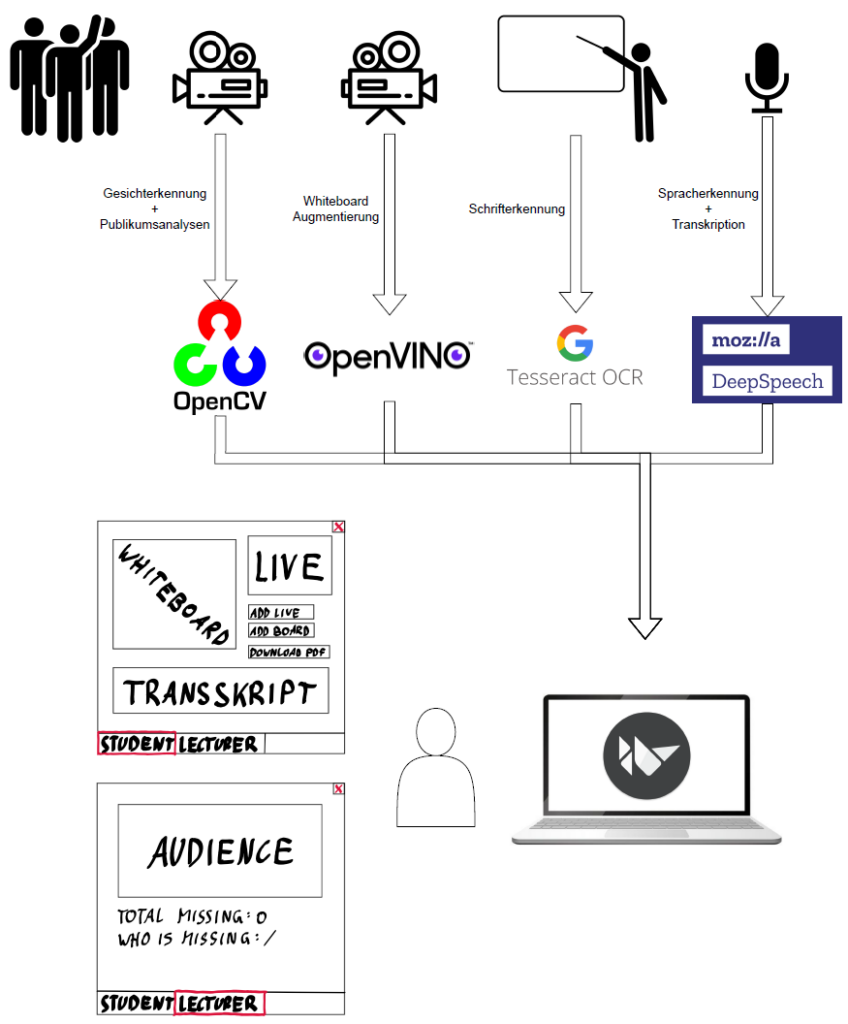
Bildverarbeitung
Für das Herausrechnen des Vortragenden wird das Toolkit OpenVino verwendet, welches mithilfe von Deep-Learning-Modellen einen Menschen vor der Tafel erkennt und nur den Inhalt hinter der Person anzeigt. Da die Berechnung dieses Modells relativ aufwändig ist, wird die Bildwiederholrate dieses Streams auf 1 Bild in der Sekunde beschränkt, um die Rechenlast so gering wie möglich zu halten. Auch für die handschriftliche Erkennung, die für die Definitionssuche benötigt wird, wird das OpenVino Toolkit verwendet.
Für die Gesichtserkennung der Zuhörer wird die Bibliothek OpenCV verwendet. In Kombination mit einem Deep-Neural-Network und trainierten Modellen können Gesichter von Personen erkannt und visualisiert werden.
Spracherkennung
Die Open-Source Speech-to-Text-Engine DeepSpeech wird verwendet, um das Gesprochene des Vortragenden zu transkribieren. Mit dieser kann in Echtzeit der gesprochene Inhalt eines Vortrags auf den
Bildschirmen der Zuhörer angezeigt werden. Wichtig für eine korrekte Spracherkennung ist eine gute Isolierung der aufgenommenen Stimme, damit etwaige Umgebungsgeräusche die Aufnahme nicht beeinflussen.
Kommunikation
Für sämtlichen Datenaustausch, darunter fallen die vier Video-Streams und der Transkript-Stream, wird die leichtgewichtige Bibliothek ZeroMQ verwendet. Mit dieser können auf Basis von Sockets einfach Daten über das Netzwerk bereitgestellt werden und anschließend von beliebig vielen Clients empfangen werden.
Benutzeroberfläche
Für die gesamte Entwicklung der grafischen Benutzeroberfläche wurde die Bibliothek Kivy verwendet. Mit dieser ist eine plattformübergreifende Programmierung von grafischen Benutzeroberflächen bei einer einzigen Codebasis möglich. Im Rahmen des Projektes beschränkte man sich jedoch auf die Windows-Plattform. Dieses Toolkit wurde aufgrund einer guten Einbindung in Python sowie einer intuitiven Benutzung gewählt.
Kameras
Bei den Kameras muss auf ausgewogene Lichtverhältnisse geachtet werden, damit die Schrifterkennung zuverlässig funktionieren kann. Zudem sollten Spiegelungen auf der Tafel vermieden werden. Der Kontrast des Kamerabildes sollte so hoch wie möglich sein, um eine gute Erkennbarkeit der Schrift zu ermöglichen. Um die Gesichter der Zuhörer erkennen zu können, muss auf eine ausreichende Auflösung von mindestens 1080p geachtet werden.
Mikrofon
Das Mikrofon sollte nahe am Mund getragen werden, passend wäre ein Headset oder ein Ansteckmikrofon. Es muss darauf geachtet werden, dass sämtliche Umgebungsgeräusche so gut wie möglich abgeschirmt und gefiltert werden. Außerdem funktioniert die Spracherkennung ausschließlich bei deutlich gesprochenem Hochdeutsch.